
Retrieval Engine
The Retrieval Engine is a powerful tool within the io.net ecosystem that enhances your AI applications with capabilities like document ingestion, intelligent file management, agentic reasoning, and conversational question answering.
Retrieval Engine allows your AI to read, view, and listen to various types of content — learning from them in real-time. Once your files are ingested, Retrieval Engine combines the insights and context from your documents to generate intelligent, grounded responses to your queries.
What is Retrieval Engine?
Retrieval Engine stands for Retrieval-Augmented Generation — a method of combining a language model with a retrieval system. Instead of relying solely on the language model's pre-trained knowledge, Retrieval Engine retrieves relevant context from your uploaded documents in real-time to answer your questions more accurately and specifically.
It’s especially useful in enterprise, research, and developer environments where accuracy, transparency, and traceability of answers are critical.
Getting Started
To begin using the Retrieval Engine System:
- Go to your io.net Dashboard.
- Navigate to the Retrieval Engine into IO Intelligence section.
- Upload your content and begin interacting with the system.

What You Can Do in the Retrieval Engine
1. Chat with Retrieval Engine
- At the bottom of the page, there is a chat field
- Simply type your question or command.
- Retrieval Engine will search through your uploaded documents and respond using context from those files.
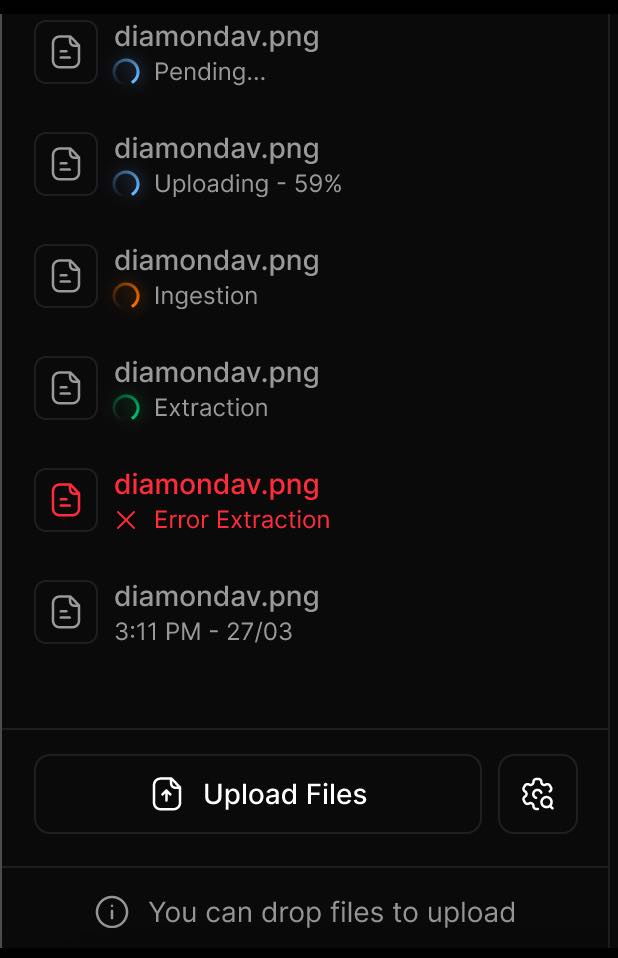
2. Upload Files
-
Click the Upload Files button or drag and drop files into the left-hand panel.
-
Supported formats: .pdf, .docx, .png, .jpg, .mp4, .html, and more.
-
Maximum file size per upload: 100MB.
Notes & Best Practices
- Make sure your files are clearly named and well-structured for better results.
- For best performance, use updated file formats and avoid scanned documents or low-quality media.
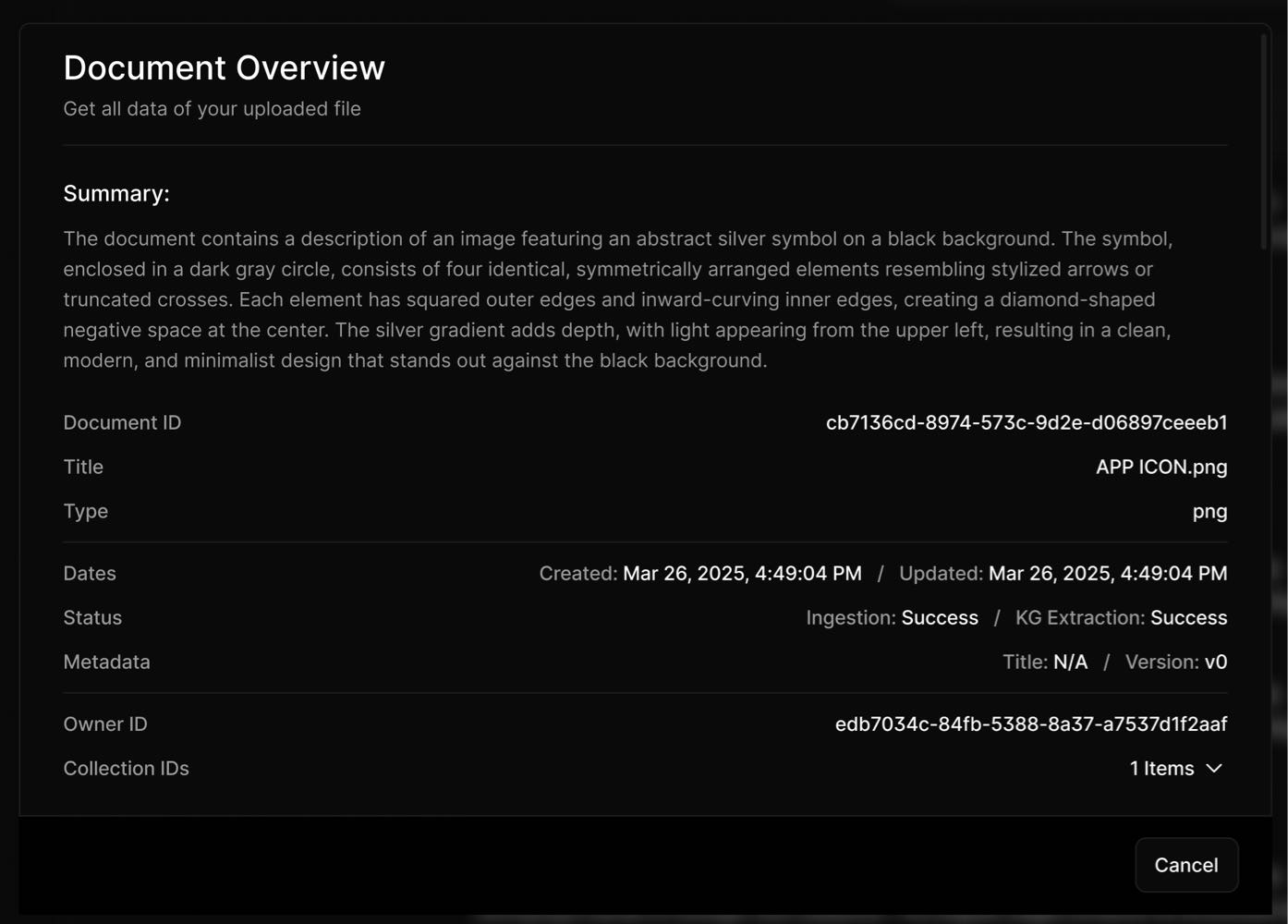
3. View File Information & Summaries
-
Hover over a file in the left panel.
-
Click the three-dot menu (⋮) next to the file name.
-
Select "File Info" to view the document’s summary and metadata generated by Retrieval Engine.
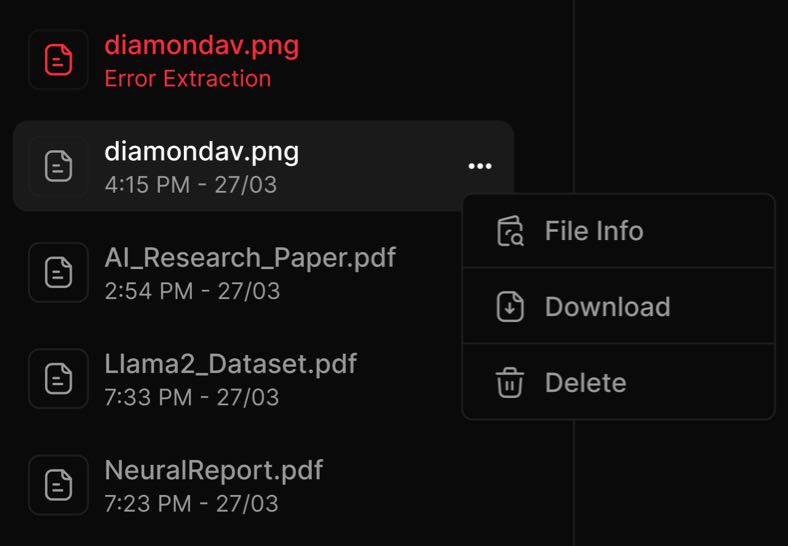
4. Delete Files
- To remove a file from your local Retrieval Engine storage:
- Hover over the file name.
- Click the three-dot menu (⋮) and choose "Delete File".
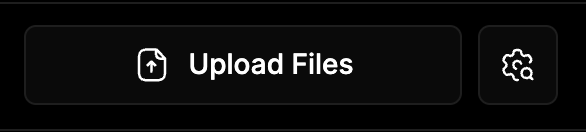
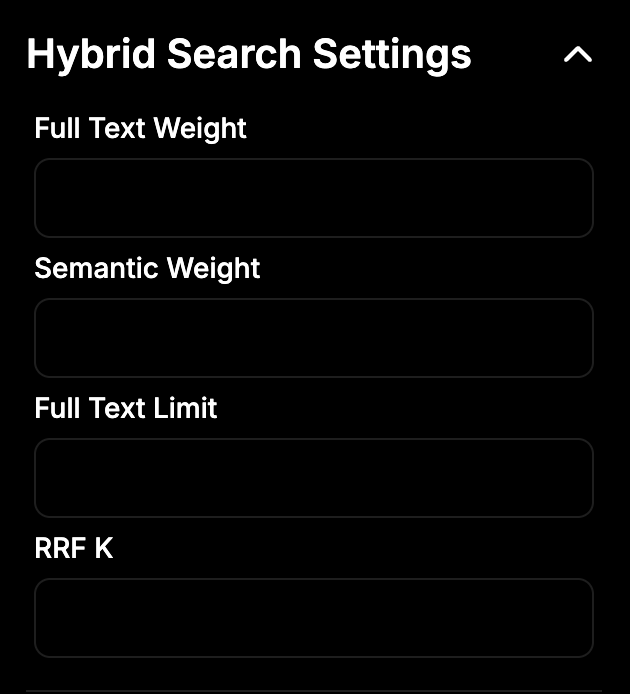
5. Search Settings
To adjust how your search works, click the Settings icon next to the Upload Files button.
Main Settings
- Vector Search – Uses machine learning to find semantically similar content, even if exact keywords aren’t used.
- Hybrid Search – Combines both traditional keyword search and semantic (vector-based) search for more accurate results.
- Graph Search – Enhances retrieval using relationships and connections between documents or data points.
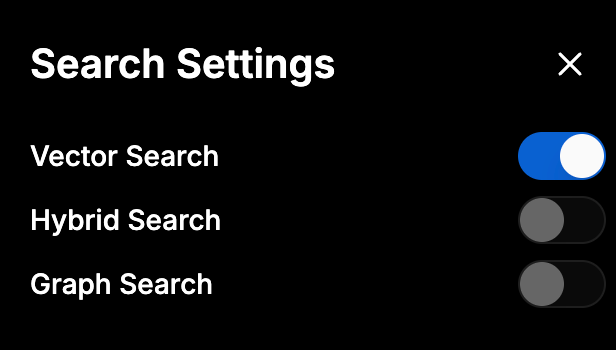
Vector Search Settings
- Search Results Limit – Number of results shown per query (default is 10).
- Index Measure – Method for comparing similarity:
- Cosine – Measures angle between vectors (commonly used).
- Euclidean – Measures straight-line distance.
- Dot Product – Multiplies and sums vector elements.
- Probes – Controls the number of partitions searched; more probes = better recall, but slower performance.
- EF Search – Trade-off setting between speed and accuracy during search. Higher = better results but slower.
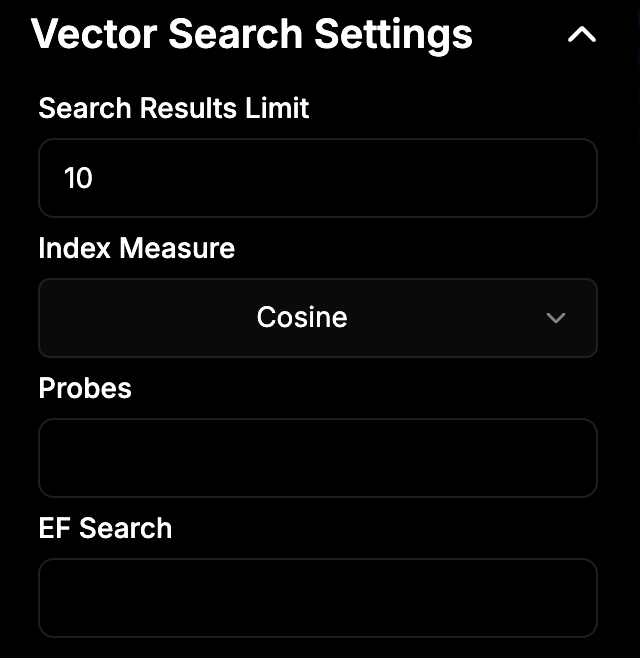
Hybrid Search Settings
- Full Text Weight – Sets how much importance to give exact keyword matches.
- Semantic Weight – Sets how much importance to give AI-based understanding of the text.
- Full Text Limit – Limits how many keyword-based results to include in hybrid search.
- RRF K – A ranking method that merges results from different search strategies. Higher K = more balanced merging.
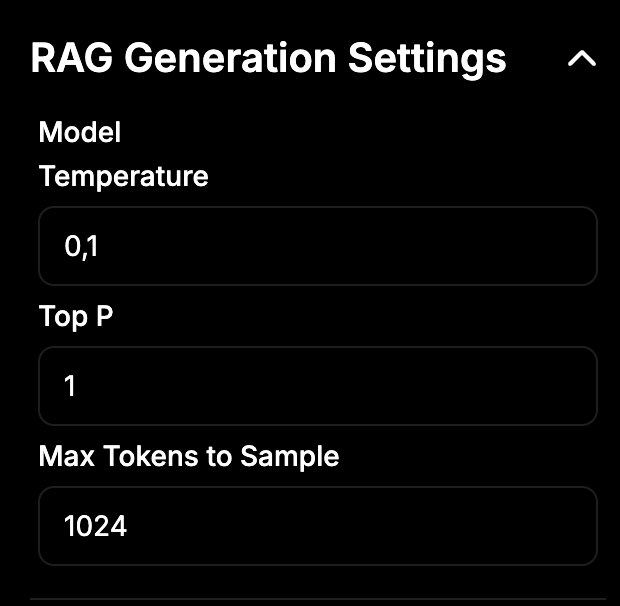
RAG Generation Settings (RAG = Retrieval-Augmented Generation)
- Model – Selects which AI model to use for generating responses.
- Temperature – Controls randomness of the AI’s responses:
- Lower (e.g. 0.1) = more focused and deterministic answers.
- Top P – Controls diversity. 1 = full range of outputs considered.
- Max Tokens to Sample – Limits how long the AI’s response can be (1024 tokens = about 700–800 words).
Communicating with the Retrieval Engine
Once your documents are uploaded:
- Enter your question in the chat field.
- Retrieval Engine will analyze your request and search through your files to provide the most accurate answer.
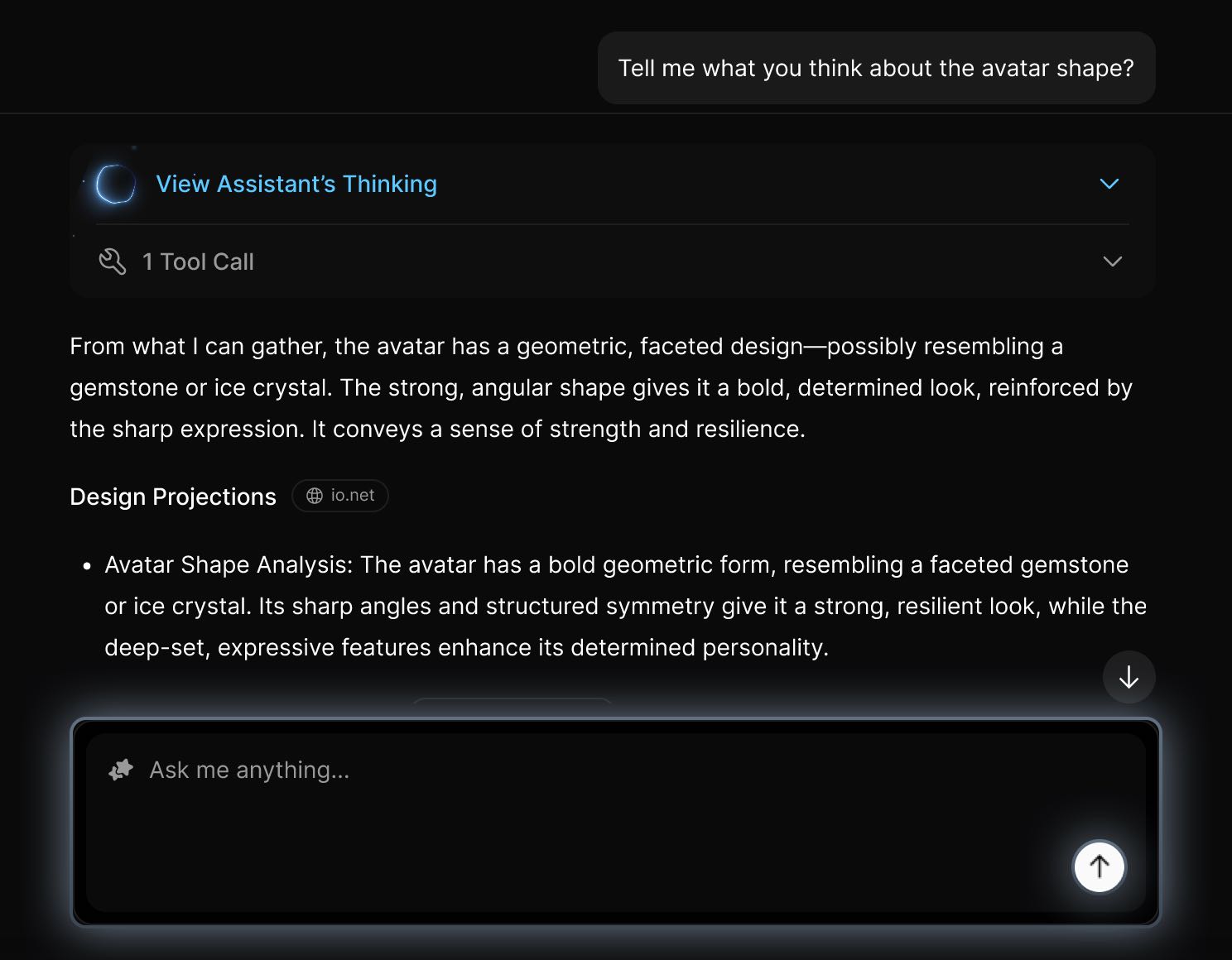
The Response Will Include:
- A clear and concise answer.
- A breakdown of Retrieval Engine reasoning path — how it arrived at that answer.
- A list of tools or agents that were used in processing your request.
- A reference to source files used — whether from your uploaded content or external sources.
Example Use Cases
- Research paper analysis
- Enterprise document summarization
- Legal document Q&A
- Media file transcription and interpretation
- Knowledge management for teams
Updated 4 months ago