
IO Intelligence API (Application Programming Interface) serves as a bridge to powerful, open-source machine learning models, deployed on IO Net hardware, allowing you to integrate cutting-edge AI capabilities into your projects with relative ease. In simpler terms, the API is like a helper that lets you use smart programs in your projects. To make the integration easy for your application, we fully support the API contract presented by OpenAI, being fully OpenAI API compatible for Chat Completions and more.
Important Note on Usage Limits
The IO Intelligence API provides the following free daily limits (measured in LLM tokens) per account, per day, per model.
Additionally, for free users, the following rate limits apply to our API endpoints. These limits are enforced using a 10-second rate limiting window:
- Chat Completion Endpoints: Up to 3 requests per second, with a maximum of 30 requests per 10 seconds
- Embeddings Endpoints: Up to 10 requests per second, with a maximum of 100 requests per 10 seconds
These limits help ensure fair usage and consistent performance across all users.
Column Definitions:
- LLM Model Name: The name of the large language model (LLM) available for use.
- Daily Chat Quota: The maximum number of tokens you can use in chat-based interactions with this model per day.
- Daily API Quota: The maximum number of tokens allowed for API-based interactions per day.
- Daily Embeddings Quota: The maximum number of tokens available for embedding operations per day.
- Context Length: The maximum number of tokens the model can process in a single request (including both input and output).
Please refer to the table below for model-specific limits:
| LLM Model Name | Daily Chat quote | Daily API quote | Daily Embeddings quote | Context Length |
|---|---|---|---|---|
| deepseek-ai/DeepSeek-R1-0528 | 1,000,000 tk | 500,000 tk | N/A | 128,000 tk |
| swiss-ai/Apertus-70B-Instruct-2509 | 1,000,000 tk | 500,000 tk | N/A | 131,072 tk |
| meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8 | 1,000,000 tk | 500,000 tk | N/A | 430,000 tk |
| openai/gpt-oss-120b | 1,000,000 tk | 500,000 tk | N/A | 131,072 tk |
| Intel/Qwen3-Coder-480B-A35B-Instruct-int4-mixed-ar | 1,000,000 tk | 500,000 tk | N/A | 106,000 tk |
| Qwen/Qwen3-Next-80B-A3B-Instruct | 1,000,000 tk | 500,000 tk | N/A | 262,144 |
| openai/gpt-oss-20b | 1,000,000 tk | 500,000 tk | N/A | 131,072 tk |
| Qwen/Qwen3-235B-A22B-Thinking-2507 | 1,000,000 tk | 500,000 tk | N/A | 262,144 tk |
| mistralai/Mistral-Nemo-Instruct-2407 | 1,000,000 tk | 500,000 tk | N/A | 128,000 tk |
| mistralai/Magistral-Small-2506 | 1,000,000 tk | 500,000 tk | N/A | 128,000 tk |
| mistralai/Devstral-Small-2505 | 1,000,000 tk | 500,000 tk | N/A | 128,000 tk |
| LLM360/K2-Think | 1,000,000 tk | 500,000 tk | N/A | 152,064 tk |
| meta-llama/Llama-3.3-70B-Instruct | 1,000,000 tk | 500,000 tk | N/A | 128,000 tk |
| mistralai/Mistral-Large-Instruct-2411 | 1,000,000 tk | 500,000 tk | N/A | 128,000 tk |
| Qwen/Qwen2.5-VL-32B-Instruct | N/A | 200,000 tk | N/A | 32,000 tk |
| meta-llama/Llama-3.2-90B-Vision-Instruct | N/A | 200,000 tk | N/A | 16,000 tk |
| BAAI/bge-multilingual-gemma2 | N/A | N/A | 1,000,000 tk | 4,096 tk |
This limit is designed to ensure fair and balanced usage for all users. If you anticipate needing a higher request limit, please consider optimizing your implementation or reach out to us for assistance.
Introduction
You can interact with the API using HTTP requests from any programming language or by using the official Python and Node.js libraries.
To install the official Python library, run the following command:
pip install openai
To install the official Node.js library, run this command in your Node.js project directory:
npm install openai
Example: Using the IO Intelligence API with Python
Here’s an example of how you can use the openai Python library to interact with the IO Intelligence API:
import openai
client = openai.OpenAI(
api_key="$IOINTELLIGENCE_API_KEY",
base_url="https://api.intelligence.io.solutions/api/v1/",
)
response = client.chat.completions.create(
model="meta-llama/Llama-3.3-70B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi, I am doing a project using IO Intelligence."},
],
temperature=0.7,
stream=False,
max_completion_tokens=50
)
print(response.choices[0].message.content)
This snippet demonstrates how to configure the client, send a chat completion request using the Llama-3.3-70B-Instruct model, and retrieve a response.
Authentication
API keys
IO Intelligence APIs authenticate requests using API keys. You can generate API keys from your user account:
Always treat your API key as a secret! Do not share it or expose it in client-side code (e.g., browsers or mobile apps). Instead, store it securely in an environment variable or a key management service on your backend server.
Include the API key in an Authorization HTTP header for all API requests:
Authorization: Bearer $IOINTELLIGENCE_API_KEY
Example: List Available Models
Here's an example curl command to list all models available in IO Intelligence:
curl https://api.intelligence.io.solutions/api/v1/models \
-H "Authorization: Bearer $IOINTELLIGENCE_API_KEY"
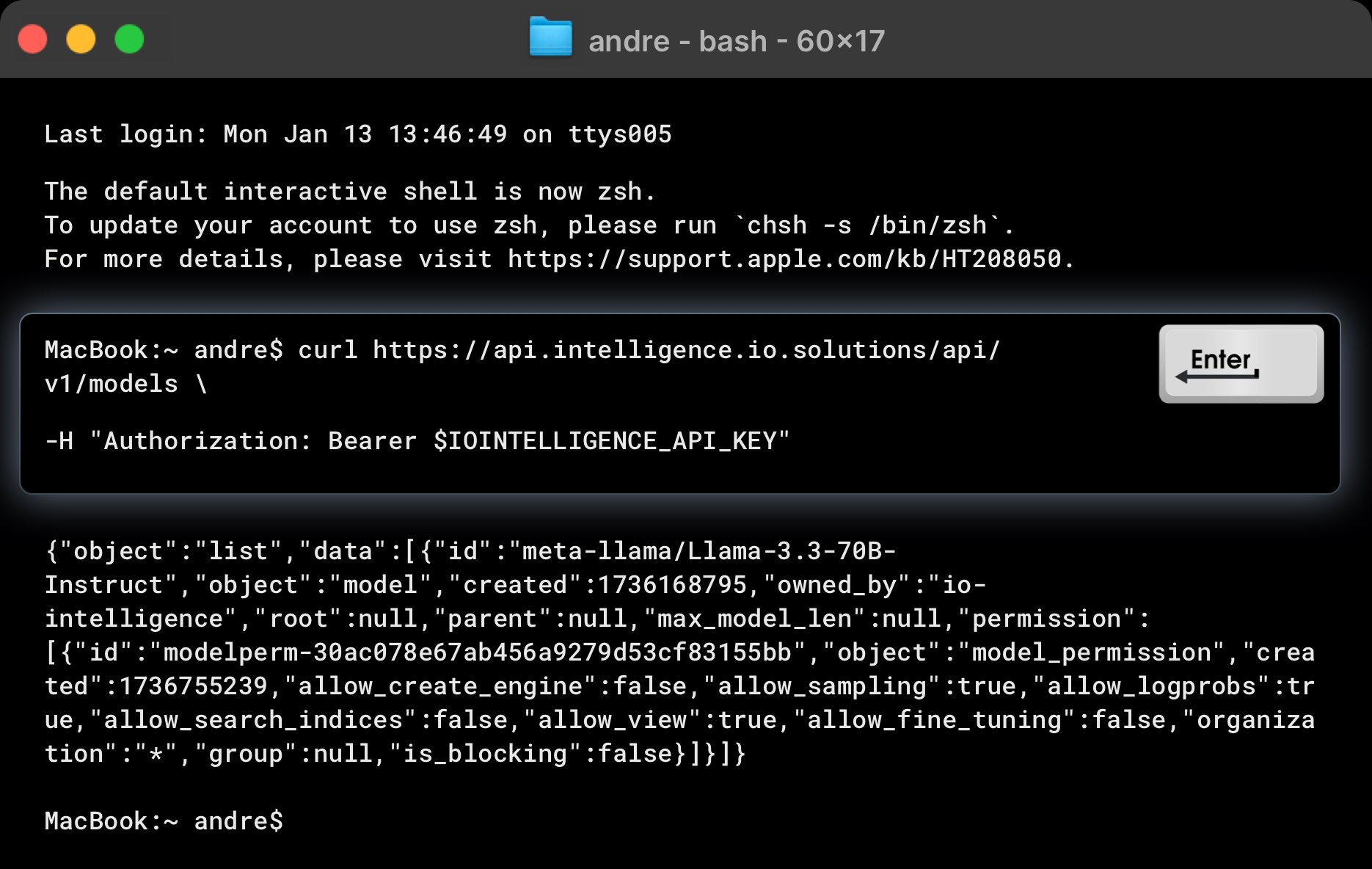
This request should return a response like this:
{
"object": "list",
"data": [
{
"id": "meta-llama/Llama-3.3-70B-Instruct",
"object": "model",
"created": 1736168795,
"owned_by": "io-intelligence",
"root": null,
"parent": null,
"max_model_len": null,
"permission": [
{
"id": "modelperm-30ac078e67ab456a9279d53cf83155bb",
"object": "model_permission",
"created": 1736755239,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
},
...
]
}
Making requests
To test the API, use the following curl command. Replace $IOINTELLIGENCE_API_KEY with your actual API key.
curl https://api.intelligence.io.solutions/api/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $IOINTELLIGENCE_API_KEY" \
-d '{
"model": "meta-llama/Llama-3.3-70B-Instruct",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"reasoning_content": true,
"temperature": 0.7
}'
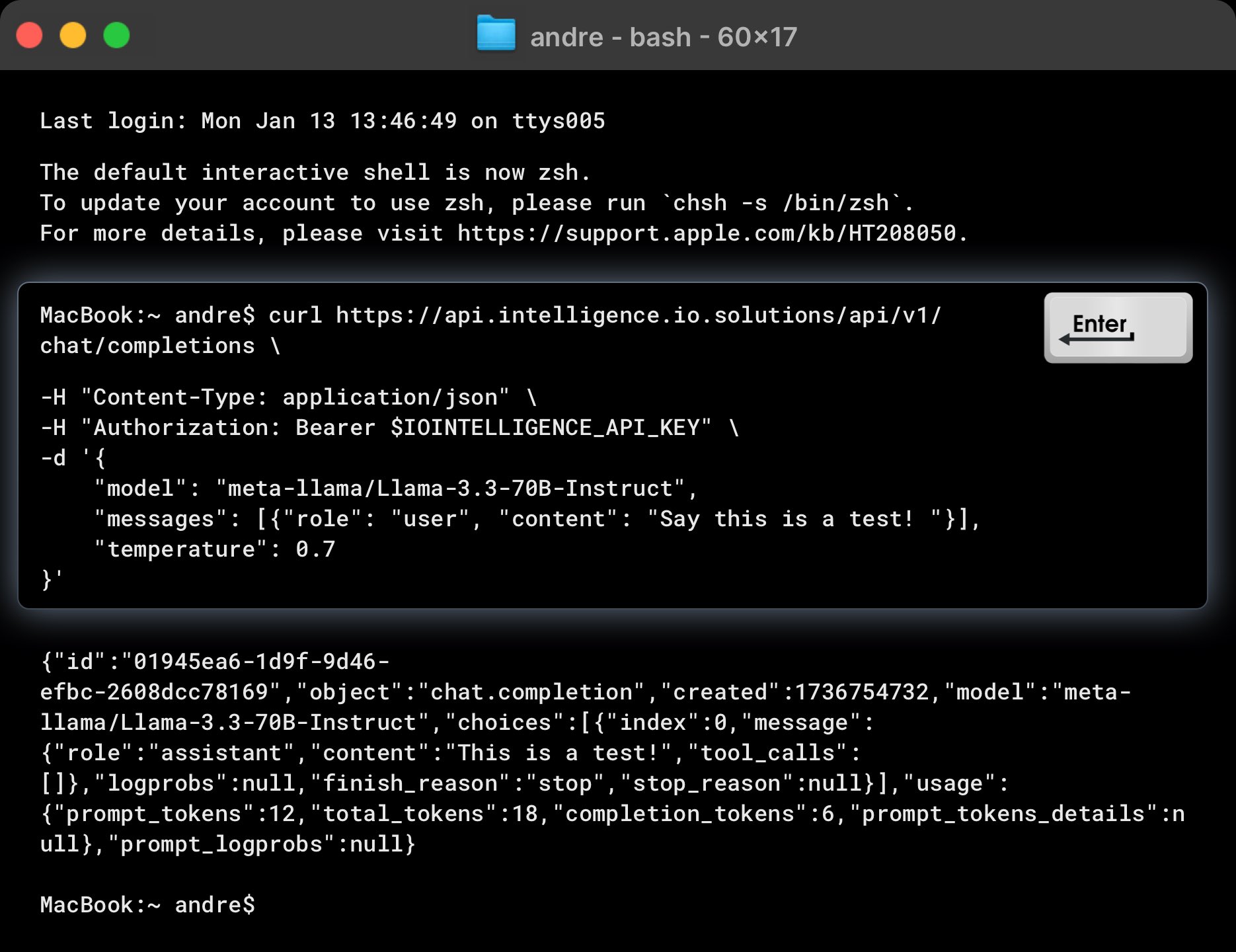
This command queries the meta-llama/Llama-3.3-70B-Instruct model to generate a chat completion for the input: "Say this is a test!".:
Example Response
The API should return a response like this:
{
"id": "01945ea6-1d9f-9d46-efbc-2608dcc78169",
"object": "chat.completion",
"created": 1736754732,
"model": "meta-llama/Llama-3.3-70B-Instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "This is a test!"
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 12,
"total_tokens": 18,
"completion_tokens": 6,
"prompt_tokens_details": null
},
"prompt_logprobs": null
}
Key Details in the Response
- finish_reason: Indicates why the generation stopped (e.g., "stop").
- choices: Contains the generated response(s). Adjust the n parameter to generate multiple response choices.
With these steps, you've successfully made your first request to the IO Intelligence API.